Generative AI
Generative AI is a category of artificial intelligence model designed to generate new data. These models are trained on large data sets that teach them to identify patterns and structure in text, images, video, and audio. Once trained, their algorithms can generate new data with similar properties in response to user input. Different models can generate paragraphs of natural-sounding text, render images in different artistic styles, or create audio samples.
Large Language Models
Generative text models (also called large language models) can generate blocks of text based on a user prompt. Even though the output may look like a person wrote it, generative text is really a form of advanced predictive text. The model generates one word at a time, predicting the next word in a sequence based on its training material. Given a large enough set of data, generative language models can generate essays, song lyrics, or even functional source code in multiple programming languages.
Different large language models use different sets of training data. The largest models use a wide variety of text, including books, news articles, social media posts, research papers, and essays. Examples of generative text models are ChatGPT, Google Bard, and Bing Chat.
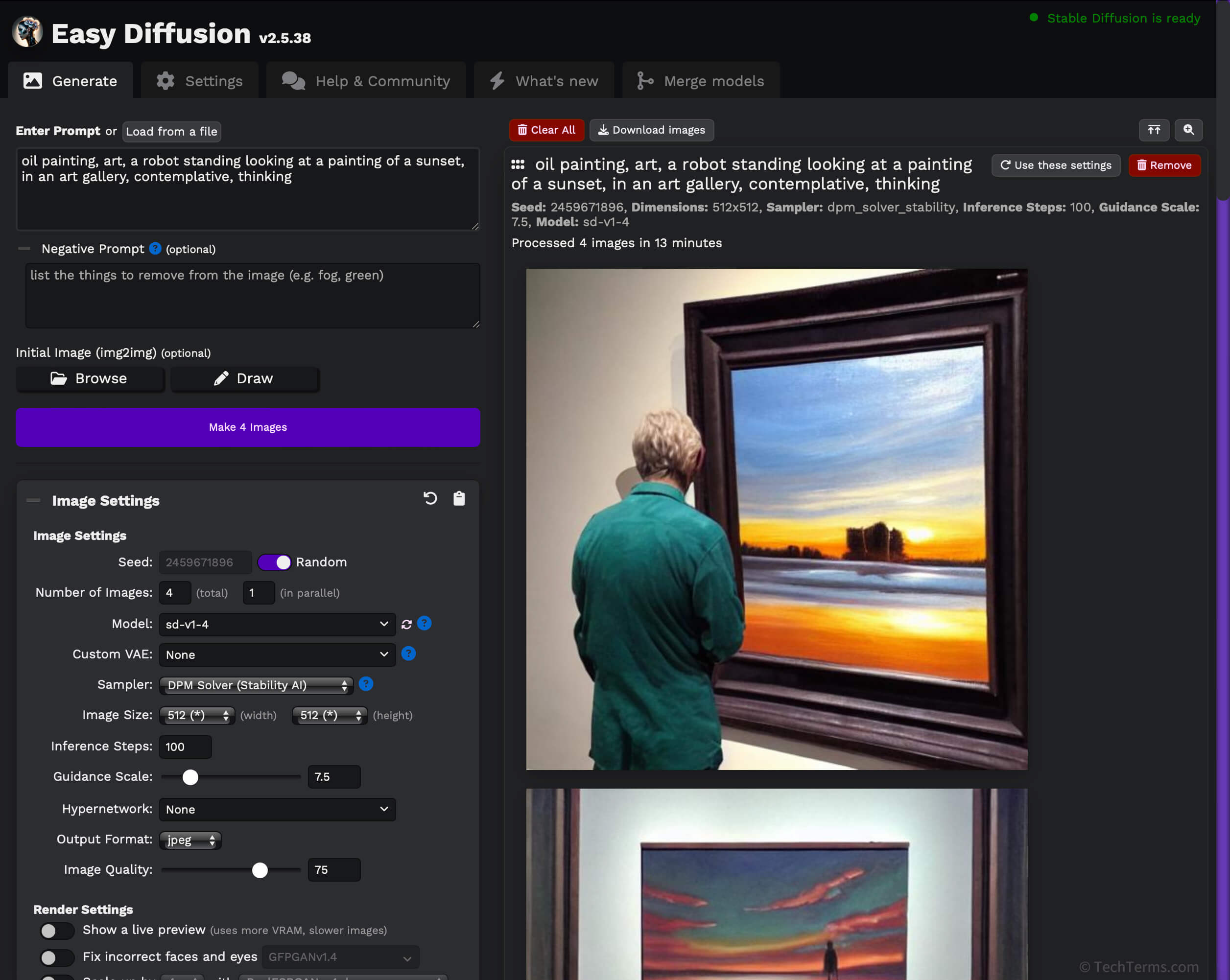
Diffusion Models
Generative image models create images using a method called diffusion modeling. These models train using machine learning — analyzing large sets of data tagged by human trainers with descriptions for both the content and artistic style of each image. The model uses these tags during training to associate specific patterns and structures within an image with the relevant text.

During training, a diffusion model first disassembles an image in a long series of steps, slowly adding random noise. After reducing the original image to static, the model slowly reassembles the image based on its content tags by generating detail to replace the random noise. It attempts this process countless times as its neural network adjusts variables until the reproduced image resembles the original. Once trained, a model can create entirely new images from a user prompt using the keywords and tags it has learned. Examples of generative image models include DALL-E, Midjourney, and Stable Diffusion.
Ethical Concerns
The rapid rise in generative AI technology comes with some ethical concerns. These models require vast sets of training data — dozens of terabytes of text for a language model and hundreds of millions of images for a diffusion model. Those training sets often include copyrighted material and can create derivative material based on those works without crediting or compensating the original creator. Training sets may also include pictures of people without their consent. Finally, whether the output of a generative AI can be copyrighted (and who owns that copyright) is a legally unsettled area.
Generative AI models are only as good as their set of training data allows, and problems within those sets may appear in a model's output. If a model's training data set includes material with biased language or imagery, it may pick up on those biases and include them in its output. While the developers of generative AI models often filter out hate speech, subtle bias is much more difficult to detect and remove. Additionally, a model trained on data that contains factually-incorrect information will pass that information along, potentially misleading its users.
 Test Your Knowledge
Test Your Knowledge